
多媒体数据压缩基本原理
课程需要掌握:
数据压缩的必要性和可能性
数据冗余的类别(3 个)
数据压缩算法的评价指标
数据压缩方法的分类(3 个)
1. 多媒体数据压缩的必要性与可能性
必要性:
多媒体信息数据巨大是多媒体计算机系统所面临的最大难题之一。在各种媒体信息中,视频信息数据量最大,其次是音频信号,因此,为了处理和传输多媒体信息不仅需要很大的存储容量,而且要有很高的传输速度。为了解决存储、处理和传输多媒体数据的问题,除了提高计算机本身的性能以及通信信道的带宽外,更重要的则是对多媒体数据进行有效的压缩。因此数据压缩编解码自然就成为了多媒体技术中最为关键的核心技术。
可能性:
2. 数据冗余的类别
此外,还有结构冗余、视觉冗余和知识冗余等。
3. 数据压缩算法的评价指标
图像质量:分为客观评估和主观评估法
压缩和解压缩的速度:根据压缩和解压缩的实时性,数据压缩又分为对称压缩和非对称压缩。
对称压缩:在有些应用中,压缩和解压缩都需要实时进行,这称为对称压缩,如电视会议的图像传输。
非对称压缩:在有些应用中只要求解压缩是实时的,而压缩可以非实时的,这称为非对称压缩,如多媒体 CD-ROM 节目的制作就采用非对称压缩。
数据的压缩和解压缩都需大量的计算。通常压缩的计算量比解压缩的计算量大。如MPEG的压缩编码计算量约为解码的 4 倍。
4. 数据压缩方法的分类
按照压缩方法是否产生失真可以分为无损压缩和有损压缩,而按照压缩方法的原理可以分为以下几种:
其中预测编码和变换编码是有损压缩,而统计编码是无损压缩。此外,还有分析-合成编码、混合编码等。
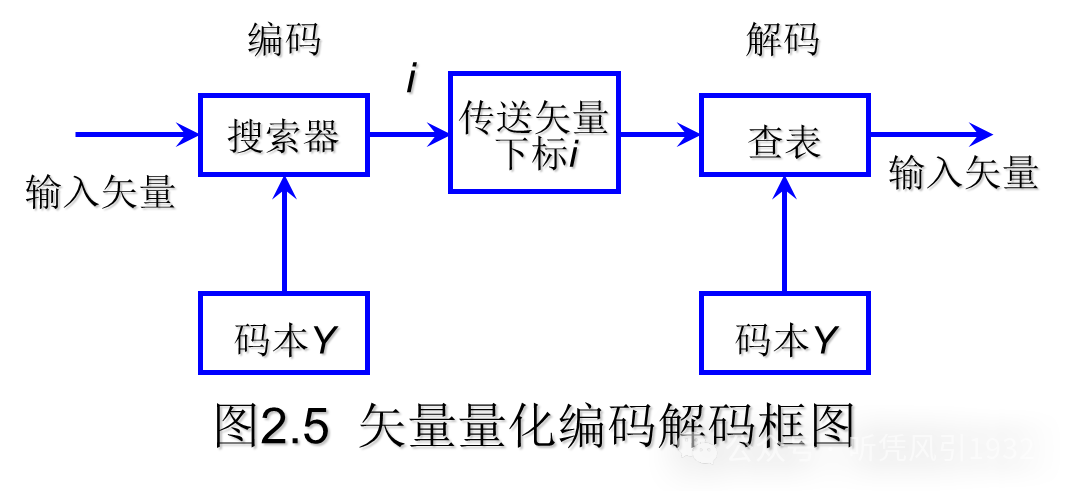
数据压缩与解压缩的常用算法
课程需要掌握:
量化的分类
信息熵的概念及公式
哈夫曼编码
算术编码
DPCM 工作原理(图)
ADPCM 的改进
K-L 变换基本原理
1. 量化的分类
按照量化的维数分:
标量量化:标量量化是一维的量化,一个幅度对应一个量化结果。
标量量化是对经过映射变换后的数据或 PCM 数据逐个进行量化,在这种量化中,所有采样使用同一个量化器进行量化,每个采样的量化都与其他采样无关,故也称为零记忆量化。
标量量化又有均匀量化、非均匀量化和自适应量化之分,即按照量化级的划分方式划分:
在下图中,(a) 图是待量化的函数,(b) 图是均匀量化,(c) 图是非均匀量化,可以看到,非均匀量化中,中间大概率处量化箱窄,两边小概率处量化箱宽。
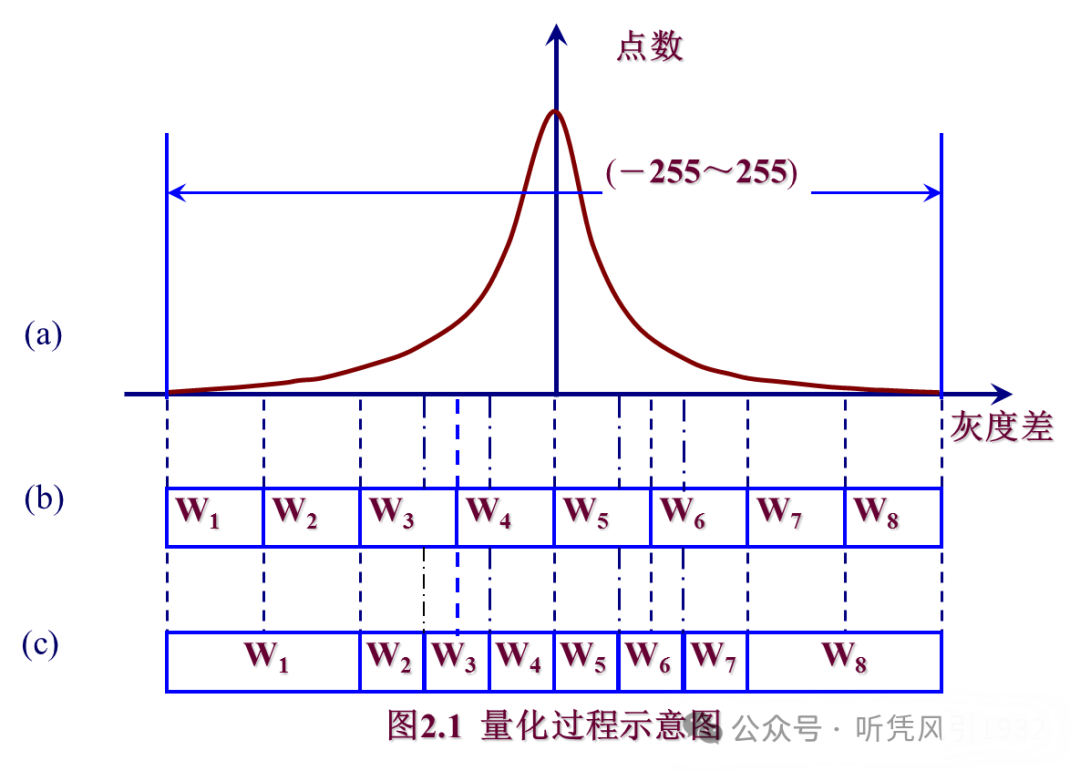
均匀量化器适合于输入信号的统计特性即概率分布密度函数均匀分布的情况。
当输入信号的概率分布密度函数分布不均匀时,最佳的量化器应是一个非均匀量化器。
矢量量化:矢量量化是二维甚至多维的量化,两个或两个以上的幅度决定一个量化结果。
矢量量化通常是将这些数据分成组,每组个数据构成一个维向量(码字),然后以矢量为单元逐个进行量化,就称为矢量量化。
由于码字在向量空间中一般呈现非均匀分布,所以在矢量量化中,很少涉及量化级的划分,一般都是非均匀的量化。
统计编码
2. 信息熵的概念及公式
信息熵是指信源所有可能事件信息量的数学期望,即信源的统计平均信息量,其单位为 bit。
可能事件的不确定性越大,熵也就越大,要确定的话所用的空间就越大。最佳的数据压缩方法的理论极限是信息熵。
3. 哈夫曼编码
哈夫曼的编码方法如下:
将符号按出现的概率由大到小排序。给最后的(即最小概率的)两个符号各赋予一个二进制码,概率大的赋 0,概率小的赋 1(反之也可)
把最后两个符号的概率加起来合成一个概率,再按大小重新排序。重新排序后重复 1 的编码过程
重复步骤 2,直到最后只剩下两个概率为止
将每个符号所对应的各分支赋的 0、1 值反向逆序排出,即得到各符号的编码。
设有信源符号集,各符号对应的出现频率分别为,其哈夫曼编码过程如下:
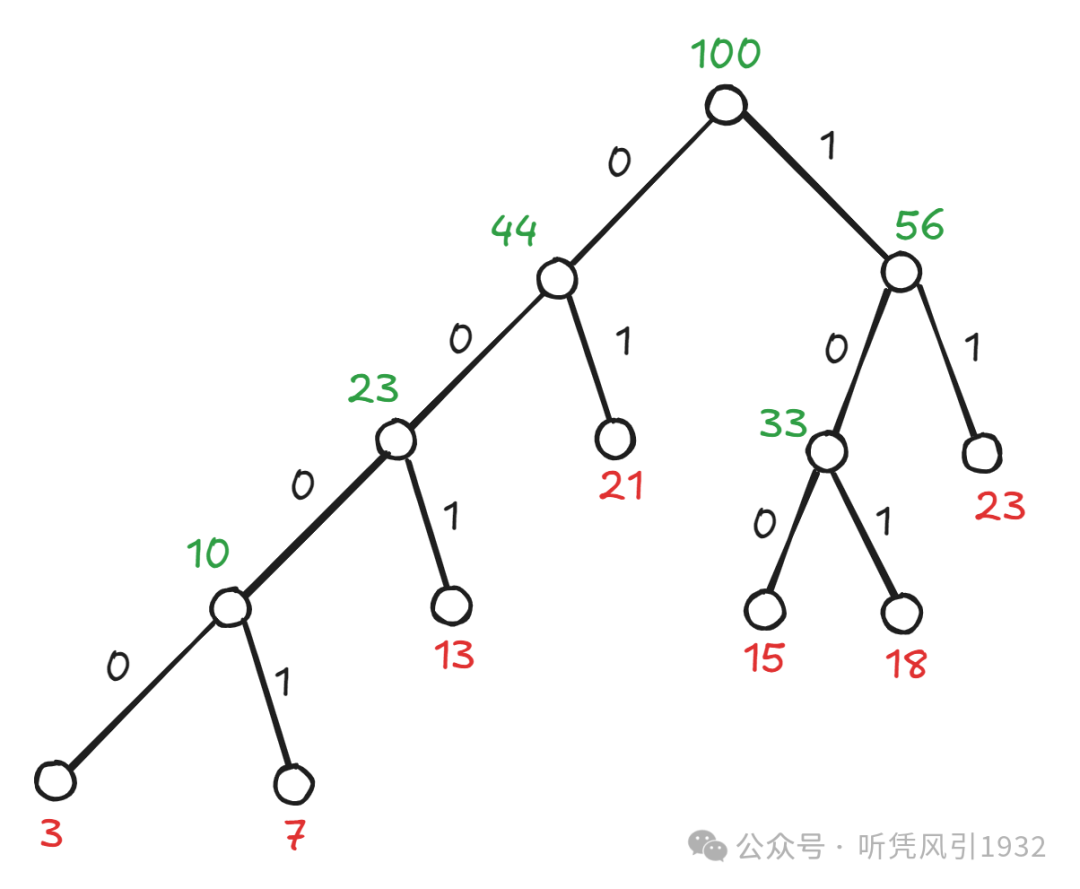
最终得到 Huffman 码为:。
需要注意到,当两个符号的出现概率相等时(在本例中是频率 0.23),谁在前谁在后是随机的,例如下图:
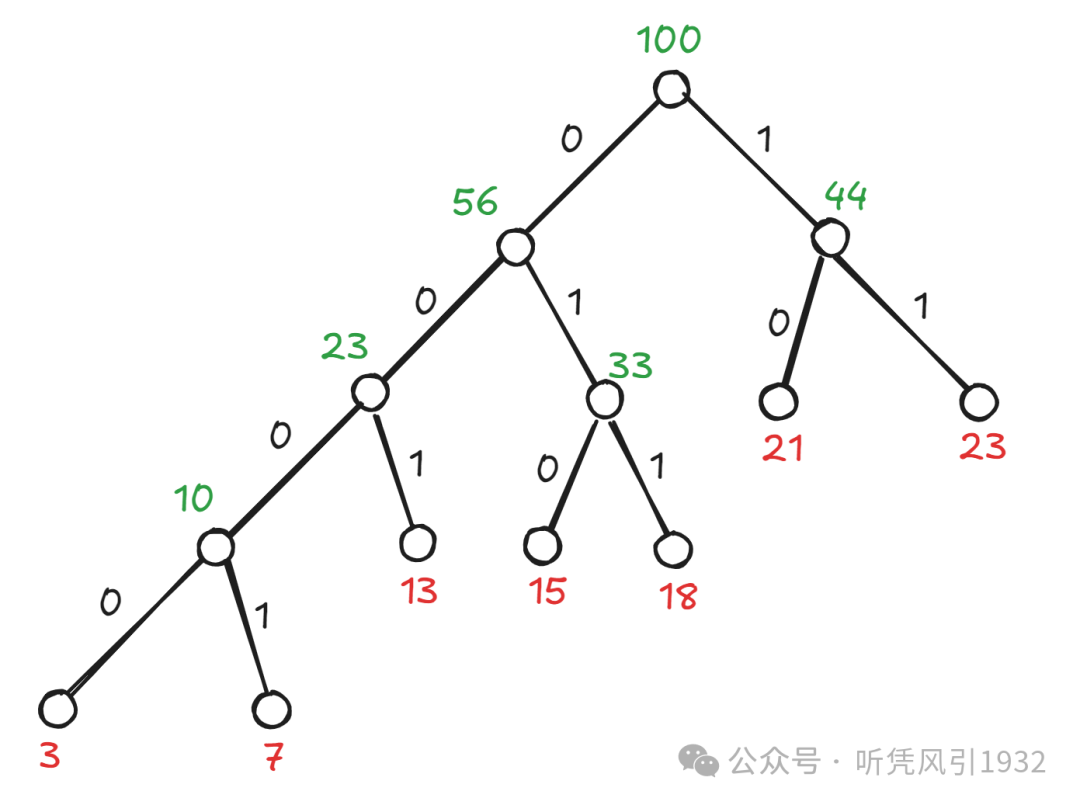
因此得到哈夫曼编码为:,上述两种是等效的,即码字的平均长度是相同的。
此外,左 0 右 1、左 1 右 0 的区别也可以产生其他的哈夫曼编码,这些都造成了编码的不唯一。
下面分别计算码字的平均长度和信源符号的熵值 :
对不同的信源,哈夫曼编码的效率也是不同的。当信源概率是 2 的负幂时,其编码效率最高,可达到 100%;当信源为等概率时,其编码效率最低。
对信源进行哈夫曼编码后形成了一个哈夫曼编码表,若要正确解码必须依照此表。于是在信源存储与传输过程中,必须首先考虑此表的存储与传输,故此表也占有一定的比特数。最好的解决方法是使用默认的哈夫曼编码表。
4. 算术编码
算术编码不按符号编码,即不是用一个特定的码字与输入符号之间建立一一对应的关系,而是从整个符号序列出发,采用递推形式进行连续编码,用一个单独的浮点数来表示一串输入符号。算术编码是将被编码的信息表示成实数 0 和 1 之间的一个间隔。信息越长编码表示它的间隙就越小,表示这一间隙所须二进位就越多,大概率符号出现的概率越大对应于区间愈宽,可用长度较短的码字表示;小概率符号出现概率越小层间愈窄,需要较长码字表示。
它的编码方法比Huffman编码方式要复杂,但它不需要传送像Huffman编码中的Huffman码表,同时算术编码还有自适应的优点,所以算术编码是实现高效压缩数据中很有前途的编码方法。
假设信源符号为{00,01,10,11},这些符号的概率分别为{ 0.1,0.4,0.2,0.3 },根据这些概率可把间隔[0,1)分成4个子间隔:[0,0.1), [0.1,0.5), [0.5,0.7), [0.7,1),其中[x,y)表示半开放间隔,即包含x不包含y。

如果二进制消息序列的输入为:10 00 11 00 10 11 01。编码时首先输入的符号是 10,找到它的编码范围是 [0.5, 0.7)。由于消息中第二个符号 00 的编码范围是 [0, 0.1),因此它的间隔就取 [0.5, 0.7) 的第一个十分之一作为新间隔 [0.5, 0.52)。依此类推,编码第 3 个符号 11 时取新间隔为 [0.514, 0.52)…… 。消息的编码输出可以是最后一个间隔中的任意数。
步骤
输入符号
编码间隔
编码判决
10
[0.5, 0.7)
符号的间隔范围[0.5, 0.7)
00
[0.5, 0.52)
[0.5, 0.7)间隔的第一个1/10
11
[0.514, 0.52)
[0.5, 0.52)间隔的最后三个1/10
00
[0.514, 0.5146)
[0.514, 0.52)间隔的第一个1/10
10
[0.5143,0.51442)
[0.514, 0.5146)间隔的第六个1/10开始的两个1/10
11
[0.514384,0.51442)
[0.5143, 0.51442)间隔的最后三个1/10
01
[0.5143836,0.514402)
[0.514384, 0.51442)间隔的从第二个1/10开始的四个1/10
从[0.5143876, 0.514402中选择一个数作为输出:0.51439
预测编码
5. DPCM 工作原理
差分脉冲调制(DPCM)预测编码并不是对每个抽样值进行独立编码,而是对根据前一个抽样值的预测值与当前抽样值的差值进行编码。因为相邻抽样值之间相关性较大,因此预测值与抽样值会很接近,其差值也会很小,因此对这个小的差值进行编码可以很有效的压缩数据量。
在DPCM系统中,需要注意的是预测器的输入是已经解码以后的样本。之所以不用原始样本来做预测,是因为在解码端(接收端)无法得到原始样本,只能得到存在误差的样本。同样地,在编码端(发送端)无法得到解码端存在误差的样本,因此,在 DPCM 编码器中实际内嵌了一个解码器,用于同步解码端的预测,模拟走一遍解码端的过程,得到。有关于内嵌解码器的解释可以参考我与 deepseek 的对话:有关为什么存在着一个内嵌译码器的解释 ,因此这里的重点是发送端的预测器的输入必须是,而不是原来的。
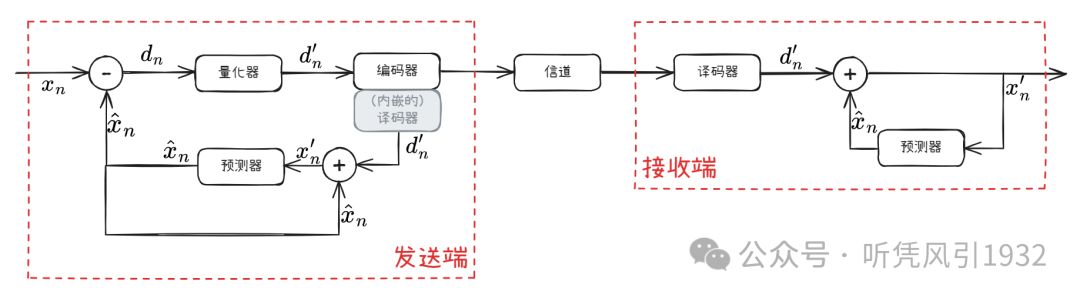
注意到,与之间的差别是由发送端量化器造成的,对的量化越粗糙,压缩比越高,所引起的失真也越大。因此,预测误差的量化是造成图像质量下降的主要原因。
针对量化器和预测器的设计,需要了解到量化器采用了非线性即非均匀量化器,而预测器是线性的。
6. ADPCM 的改进
自适应差分脉冲调制(ADPCM)的改进思想与原理:
DPCM 系统的基础是输入数据为平稳的随机过程,这样就可以用固定的参数来设计预测器。然而,当输入数据并非是所要求的平稳的随机过程时,或总体上平稳,但局部不平稳时,使用固定的参数来设计预测器将是不合理的。这时可采用自适应预测编码的方法,即定期地重新计算协方差矩阵和相应的加权因子,充分利用其统计特性重新调整预测参数,使预测器随着输入数据的变化而变化,从而得到较为理想的输出。
自适应预测又可分为线性自适应预测和非线性自适应预测两种。
变换编码
变换编码方法有 KL 变换、离散余弦变换 DCT 等,这里仅针对 KL 变换做说明。
7. K-L 变换基本原理
K-L变换也常称为主成分变换 (PCA), 是一种基于图像统计特性的变换,它的协方差矩阵除对角线以外的元素都是零,消除了数据之间的相关性,从而在信息压缩方面起着重要作用。
需要注意到,K-L 变换是多种变换编码方式中的最佳变换,其实现难度也是最大的,计算量也很大。
多媒体数据常用压缩标准
课程需要掌握:
不同质量的音频压缩标准
JPEG 的 2 种编码方法
基于 DCT 并应用行程编码和熵编码的有失真压缩算法
基于 DPCM 的无失真压缩方法
JPEG 基于 DCT 的有失真压缩编码过程
MPEG-1 标准数据码流结构
为了同时满足高压缩比和随机存取的要求,MPEG 定义的 3 种图像及生成过程
I、P、B 图像的压缩编码算法
MPEG-2 标准目标(高质量,宽带宽,灵活性,兼容性)
MPEG-4 标准最突出特点(基于内容/对象的压缩编码方法)
AVO(Audio/Video Object)的概念
MPEG-4标准关键技术(DMIF,语法描述,音频对象的编码,视觉对象的编码)
MPEG-4标准数据码流结构(视频段VS,视频对象VO,视频对象层VOL,视频对象平面VOP)
MPEG-4标准编码过程(形状编码,运动编码,纹理编码)
1. 不同质量的音频压缩标准
2.JPEG 的 2 种编码方法
JPEG采用了混合编码方法,定义了两种基本压缩算法:
基于空间线性预测技术(即DPCM)的无失真压缩方法
JPEG 压缩标准的有失真压缩率为~,而无失真压缩率大约为。任何算法所能实现的数据压缩量与被压缩的图像的特性有关,也与应用所要求的画面质量相关。
3. JPEG 基于 DCT 的有失真压缩编码过程
JPEG 基于 DCT 的编码过程为:先进行 DCT 正变换,然后再对 DCT 系数进行量化,并对量化后的直流(DC)系数和交流(AC)系数分别进行差分编码和行程编码,最后再进行熵编码。编码过程的简化框图如下:
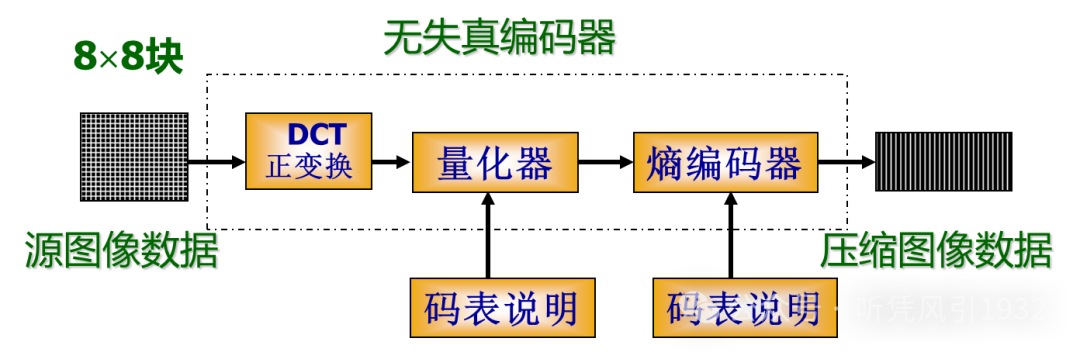
更详细地,可以有如下步骤:
切割分块
JPEG 采用子块为 8×8的二维 DCT 变换。在编码器的输入端,把原始图像顺序地分割成一系列 8×8 的子块。划分方法:从左到右,从上到下。
进行 DCT 正变换
DCT 的输出是 64 个基信号的幅值,称作 DCT 系数,这 64 个 DCT 系数中,处于最左上角的是直流系数(DC),其余 63 个是交流系数(AC)。直流(DC)系数幅度最大,频率最低。离 DC 分量越远,频率越高,幅度值越小。
DCT 系数的量化
量化定义为,对 64 个 DCT 变换系数,除以量化步长,四舍五入取整得到。
量化器步长是量化表的元素,由于人眼对亮度信号比对色差信号更敏感,因此亮度量步长小于对应的色度量化步长。考虑到人眼对低频分量的图像比对高频分量的图像更敏感,因此量化表中左上角量化步长比右下角量化步长小。总结下来就是越敏感的量化步长越小,人眼对亮度信号与低频分量敏感。
量化后处理
量化后的 DCT 系数要重新编排,这样做可以增加连续的“0”系数的个数,也就是说尽量增加“0”行程长度,最好的办法是采用“Z 字蛇行”扫描,
编码
使用差分脉冲编码调制(DPCM)对直流系数进行编码,因为直流系数数值变换不大。
使用行程编码(RLE)对交流系数进行编码,因为在 d 步骤中有多个连续的 0。
根据数据符号出现的概率高低进行熵编码(哈夫曼编码),从而实现进一步压缩。
组成位数据流
这是 JPEG 编码的最后一个步骤,即把各种标记代码和图像编码后的图像数据组成一帧一帧的数据,以便于传输、存储和译码器译码。
4.MPEG-1 标准数据码流结构
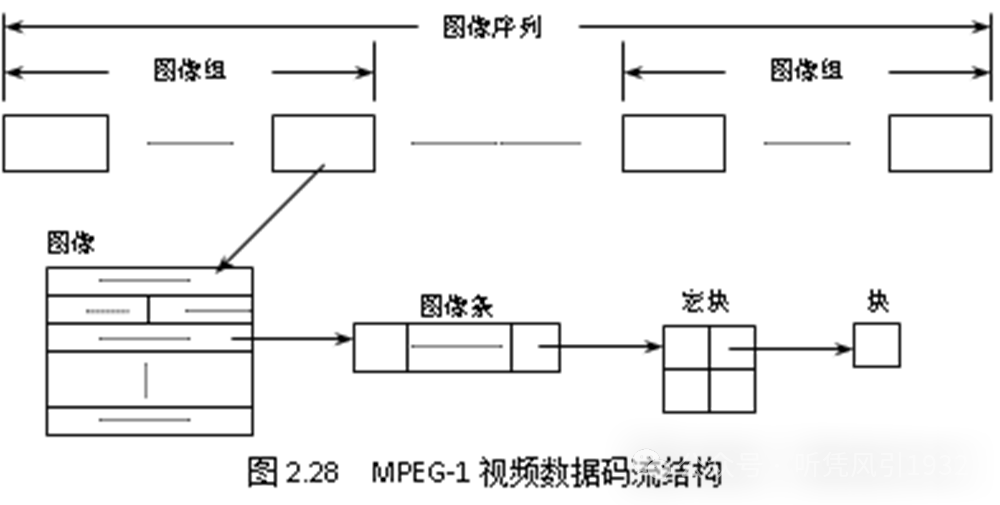
按照从小到大的顺序有:
块:MPEG-1 算法中最小的编码单元,它包含着 8×8 像素,是帧内编码的基本单元,即进行 DCT 的基本单元。
宏块:MPEG-1 算法中的基本编码单元,即进行运动补偿的基本单元。它由图像帧内的16×16 像素的亮度信息和两个 8×8 像素的色度信息组成。
图像条:图像帧内的水平条,只有当条中的所有像素都有效时,块和宏块的编码操作才能完成。
图像:显示和编码的基本单元,对应于视频序列中单个帧。
图像组:图像组一般由一个 I-图像帧、几个 P-图像帧和若干个 B-图像帧构成,是进行随机存取的单元,称为 GOP,它由数据头及若干图像组成,数据头包含时间代码等信息。
图像序列层:图像序列层是最高层,它由一个数据头及若干 GOP 组成。数据头包含了图像的大小、分辨率、帧率,量化表的类型等信息。
5. MPEG 定义的 3 种图像及生成过程
为了同时满足高压缩比和随机存取的要求,MPEG 定义了 3 种图像:I 图像(帧内图像)、P 图像(预测图像)和 B 图像(双向预测图像)。通过帧内使用 DCT 实现随机存取,通过帧间预测使用 DCT 实现高压缩比。
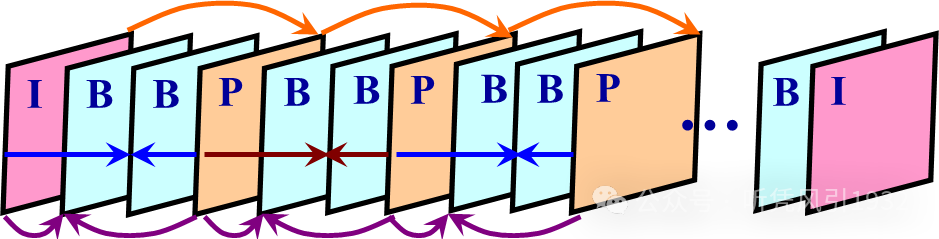

6. I、P、B 图像的压缩编码算法
帧内图像 I 的压缩编码算法(帧内编码)
帧内图像 I 不参照任何过去的或者将来的其他图像帧,压缩编码采用JPEG 压缩算法中基于 DCT 的有失真压缩算法。如果电视图像是用 RGB 空间表示的,则首先把它转换成 YUV 空间表示的图像。后续的步骤与JPEG 基于 DCT 的有失真压缩编码过程相同。
预测图像 P 的压缩编码算法(帧间编码)
P 图像是用前面最近的一个 I 图像(或 P 图像)预测编码得到的(前向预测),为了减少动态图像的时间冗余,这里采用了运动补偿的预测编码。预测图像的编码是以图像宏块为基本编码单元 ,一个宏块一般定义为 16×16 像素的的图像块。
基于宏块的运动补偿技术,就是在其参照帧中寻找符合一定条件,与当前被预测块匹配最佳的宏块。
如何找到最佳匹配块?预测图像 P 使用两种类型的参数来表示:一种参数是当前要编码的图像宏块与参考图像的宏块之间的差值,另一种参数是宏块的移动矢量。依据这两个参数即可找到最佳匹配块。
找到最佳匹配块后,对预测的误差采用ADCT技术编码,在恢复被预测块时,用匹配块加上预测误差即可。
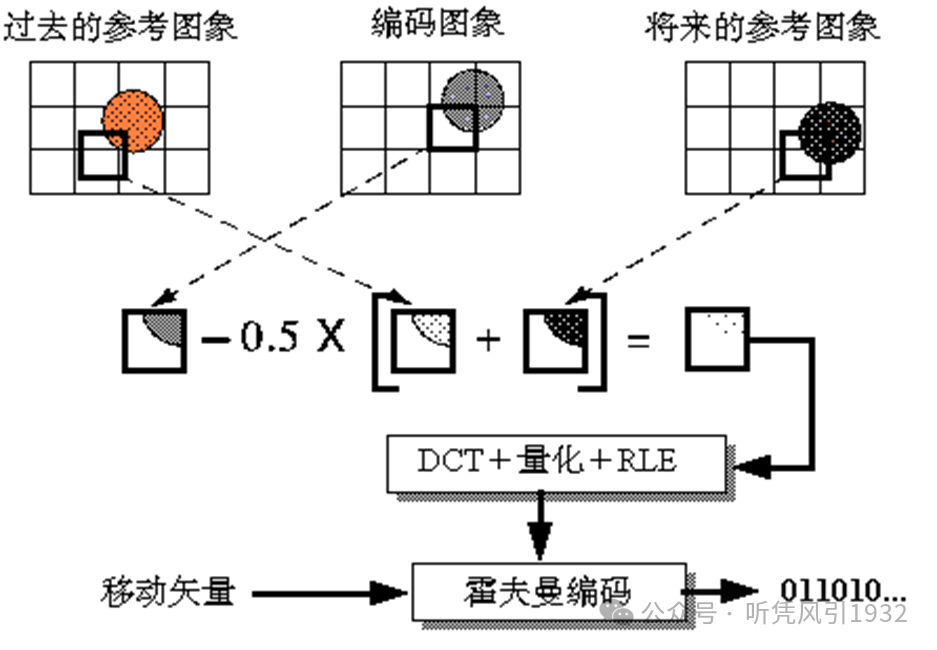
双向预测图像 B 的压缩编码算法(帧间编码)
双向预测图像 B 在预测时,同时使用前后两个图像作为参照图像(双向预测)。其压缩编码算法框图如下:
7. MPEG-2 标准目标
8. MPEG-4 标准最突出特点
与 MPEG-1、MPEG-2 相比,MPEG-4 最突出的特点是基于内容/对象的压缩编码方法。它突破了 MPEG-1、MPEG-2 基于块、像素的图像处理方法,而是按图像的内容如图像的场景、画面上的物体(物体1、物体2)等分块,即将感兴趣的物体从场景中截取出来,称为对象或实体。MPEG-4 便是基于这些对象或实体进行编码处理的。对每一个对象的编码形成一个对象码流层,该层码流中包含着对象的形状、尺寸、位置、纹理以及其它方面的属性。
9. AVO 的概念
为了具有基于内容方式表示的音视频数据,MPEG-4 引入了 AVO(Audio/Video Object)的概念。AVO 的构成依赖于具体应用和系统实际所处的环境,它可以是一个没有背景的说话的人,也可以是这个人的语音或一段背景音乐等,它具有高效编码、高效存储与传播以及可交互操作的特性。
当VO被定义为场景中截取出来的不同物体时,它有三类信息来描述:运动信息、形状信息和纹理信息。MPEG-4 标准的视频编码就是针对这三种信息的编码技术。
10. MPEG-4 标准关键技术
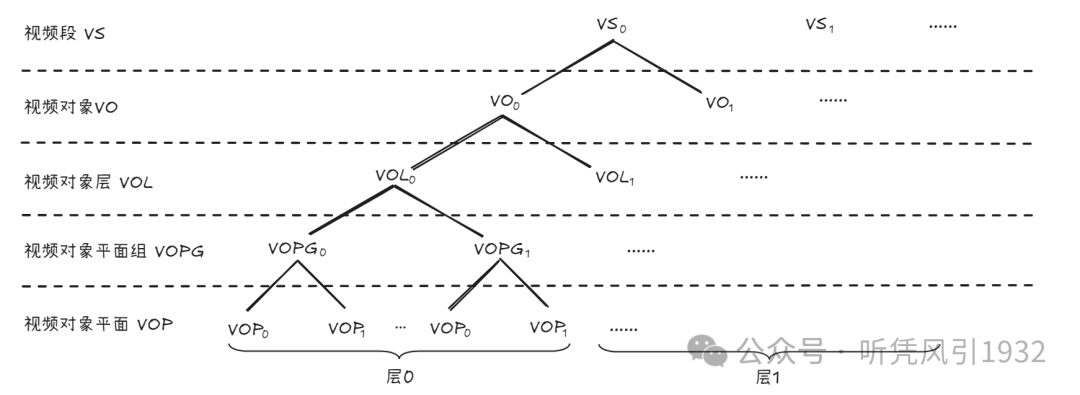
11. MPEG-4 标准数据码流结构
12. MPEG-4 标准编码过程
形状编码
MPEG-4 标准中,形状编码的信息分为两类:二值形状信息和灰度级形状信息。这两类信息均可采用位图法来表示。
位图法:一个从场景中截取出的 VOP(视频对象平面)是一个不规则的形状, VOP 被一个边框框住,边框长、宽均为 16 的整数倍,同时保证边框最小。位图表示法实际上就是一个边框矩阵,于是编码就变为对这个边框矩阵的编码。
二值形状信息就是用 0 和 1 表示 VOP 形状的信息,1 表示 VOP 形状的区域,0 表示非 VOP 形状区域。
灰度级形状信息可取0~255,1~255 表示 VOP 区域透明程度的不同,0 表示透明区域,即非 VOP 区域。
运动编码
运动信息是反映 VOP 随时间变化的信息,通过运动估计和运动补偿,可消除 VOP 的时间冗余,从而提高编码效率。类似于 MPEG-1 中的 I 帧、P 帧和B 帧 3 种帧格式,MPEG-4 中的 VOP 也有三种相应的帧格式,分别是 I-VOP、P-VOP 和 B-VOP,以表示 VOP 的运动补偿类型的不同。
只有对 P-VOP 和 B-VOP 编码时才需要运动估计。运动估计可基于16×16的宏块,也可基于8×8的块。
对 VOP 各部分的运动编码方法:
对处于 VOP 外但在边框内的宏块(透明宏块),不进行运动估计;
对完全处于VOP内的宏块,就采用一般的基于 16x16 像素宏块或 8x8 像素块运动估计,这样这个宏块只有一个运动矢量;
对部分在 VOP 内,部分在 VOP 外的宏块,则采用“多边形匹配”技术进行运动估计,匹配误差由属于VOP内部的像素与参考宏块对应位置像素差的绝对值的和(SAD)来度量。
纹理编码
VOP 的纹理信息包含在视频信号的亮度分量 Y 和两个色度分量 U 和 V 中。对于帧内编码的I-VOP,纹理信息直接包含在亮度和色度分量中,而对于帧间编码的P-VOP、帧间双向估计编码的B-VOP,纹理信息包含在的运动补偿后的残差中,这两类纹理信息均采用基于 8×8的块DCT方案来编码。
对 VOP 各部分的纹理运动编码方法:
对处于 VOP 外但在边框内的块(透明块),不进行编码;
对完全位于 VOP 内的块,进行传统的 DCT 编码;
对部分在 VOP 内,部分在 VOP 外的块,先用“重复填充”技术对该块在 VOP 外的部分进行填充,填充后的块编码方法与内部块一样,即进行传统的DCT编码。